Caching Patterns
Introduction
How many heard the phrase “Cache invalidation is the toughest problem in computer science?” I was first introduced to the term “cache” in my computer architecture class in engineering. When I first learned, I did not understand the concept. It took me some years to wholly understood the concept. In this blog post, we will look at the basics of caching and different strategies.
Basics
What is caching? caching is a mechanism of storing data in fast and secondary storage temporarily. The main goal of caching is to decrease the response time and increase speed. The fundamental concept is simple, primary storage gives persistence and durability that stores the data permanently. But, they are slow. We need secondary storage that is fast but temporary. That’s what the RAMs are designed for. They are fast but the data stored in them is temporary. We also call RAM in-memory. Let’s try to understand the mechanism with the diagram below.
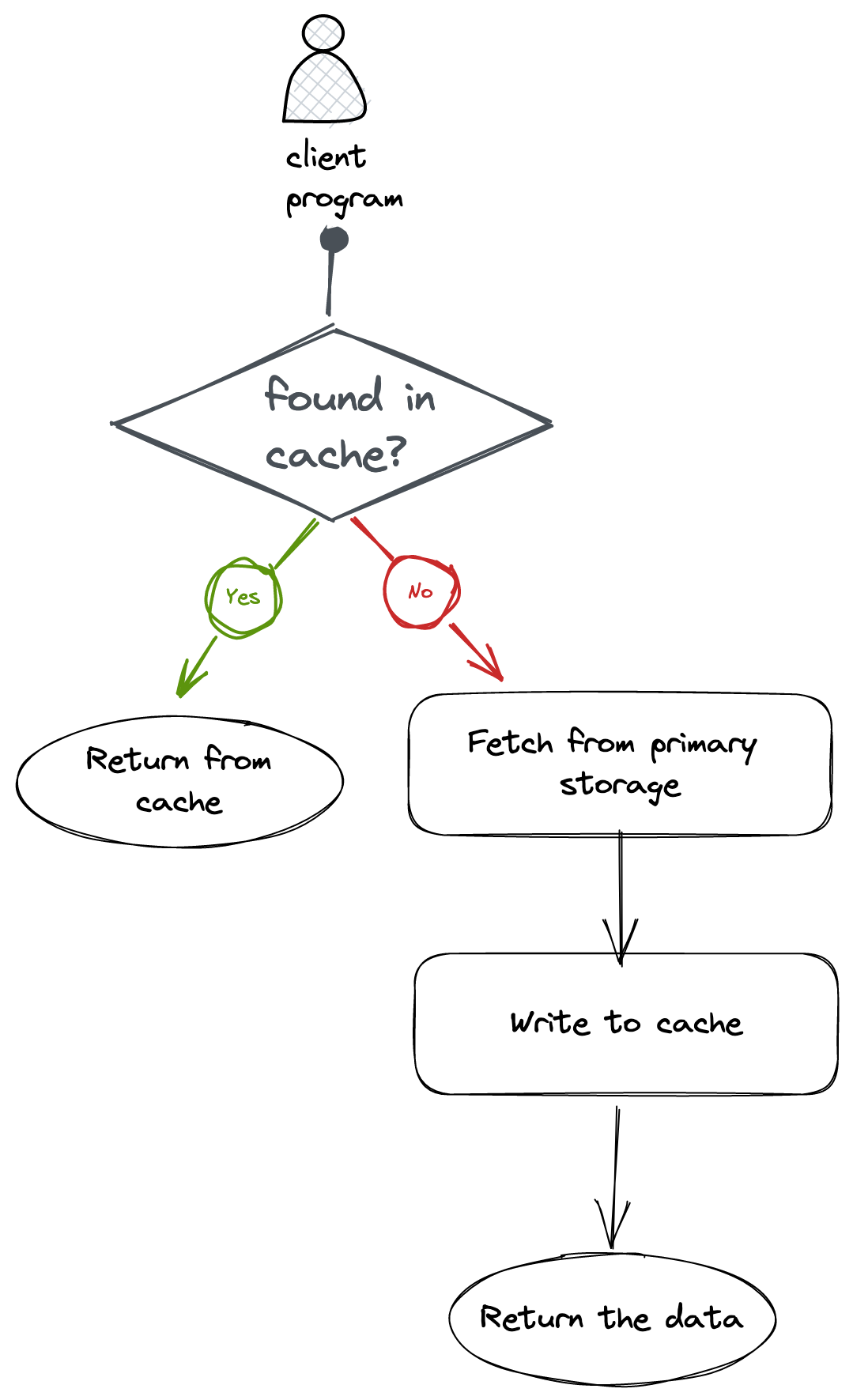
The above diagram is a no-brainer. We first check in the cache because it’s fast, if not found fetch it from primary storage and write it back to the cache.
Caching is implemented in different use cases. A few of them are
- Disk page caching: Hard disks are cylindrical structures divided into sectors, tracks, and pages. A page is a continuous block of memory. Accessing the hard disk every time requires an I/O overhead and CPU context switching. To optimize this, the UNIX operating system caches the pages in the main memory.
- Web server caching: Web servers like nginx caches the frequently accessed pages to increase speed and responsiveness. They simply store the entire HTML content in the main memory and serve from there.
- Application level caching: Applications like web browsers, code editors and your backend web APIs cache the result in in-memory.
Cache Eviction Policies
The capacity of our RAM is of some fixed size. So, when it reaches its size, it needs to omit some data. This process is called eviction. Below are different eviction techniques used.
Least Recently Used
As the name says, remove the least recently used entry. A doubly linked list data structure is used commonly to implement this mechanism. The data is stored in the sorted order of access where the most recently used at the beginning and the least recently used at the end. Every time a cache key is accessed, it will be put at the front.
Least Frequently Used
A frequency count of each cache key will be maintained. Every time a key is accessed, the frequency count will be updated. Whenever the cache reaches its size, the less frequent item will be removed.
Caching Patterns
There are different patterns of caching. We will look at each of them.
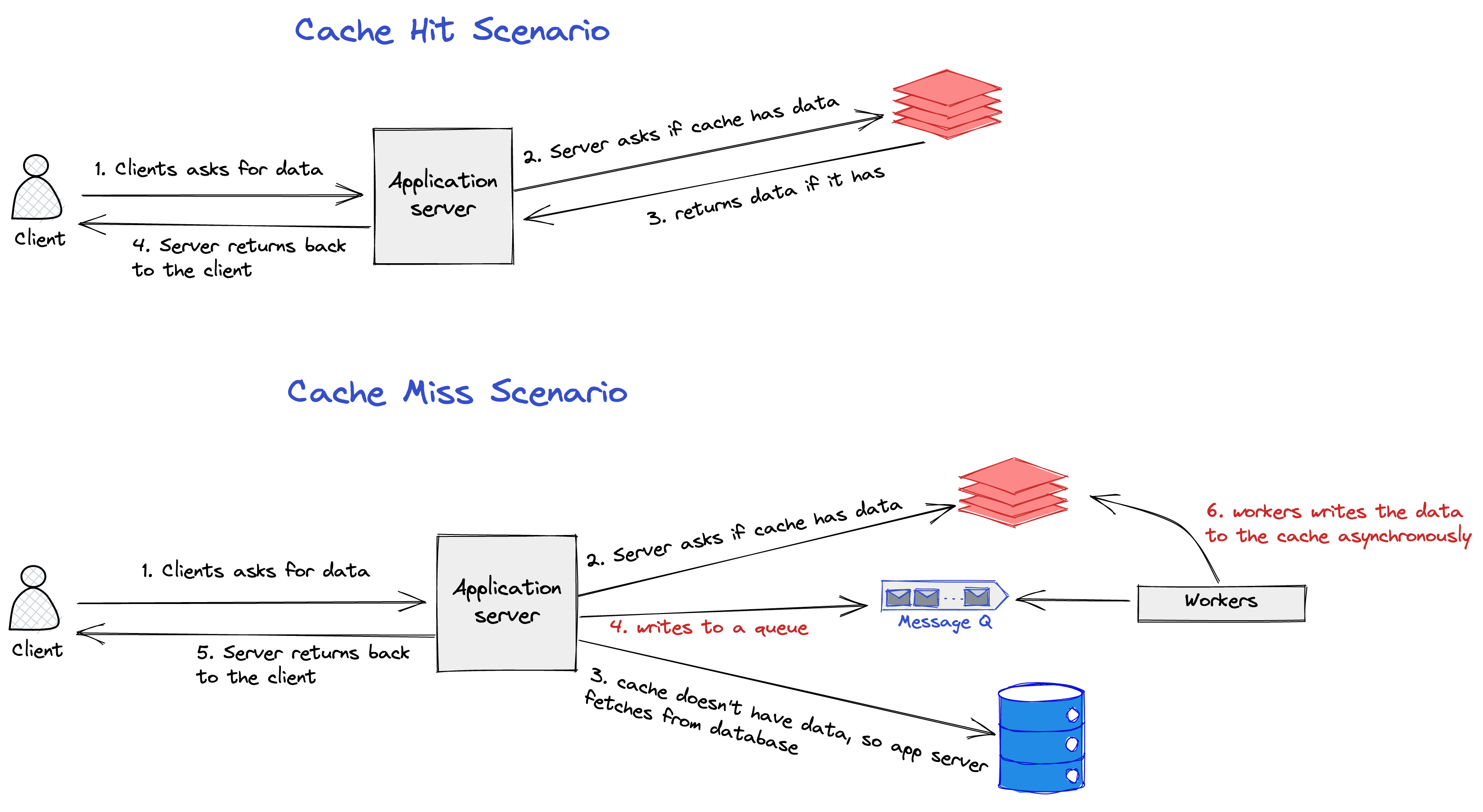
Cache Aside
This is the most common pattern. We already discussed this in the above flow diagram. We will first check in the cache, and if not found, read from the database and write to the cache again.
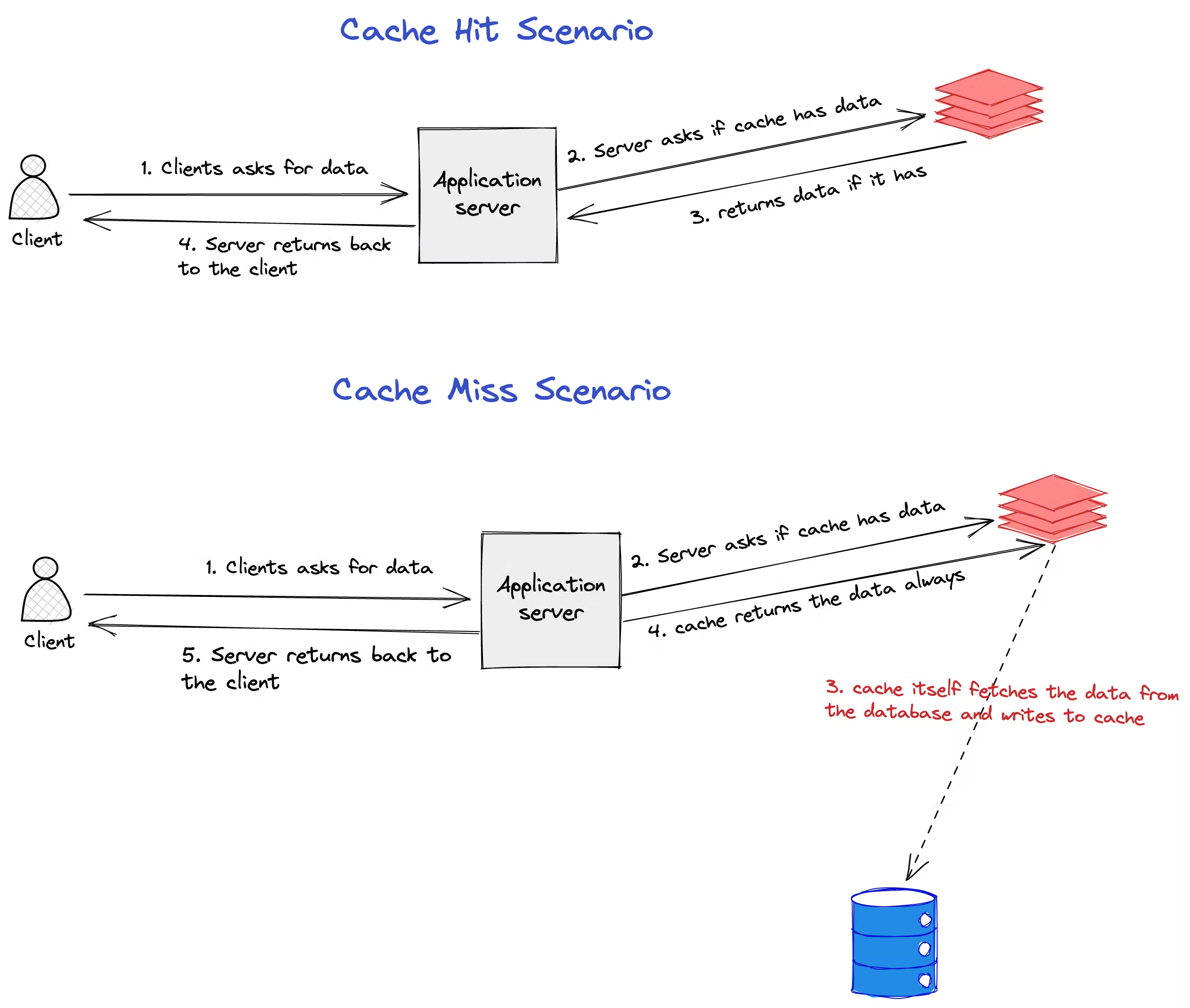
Read Through
In cache through pattern, the application server asks the cache for the data, in case of a cache miss, the cache itself fetches from the database and saves in the cache. In order to implement this pattern, the caching software should have libraries to integrate with the database technology. Very few caching software implement this pattern. An example is AWS DAX which integrates with DynamoDB.
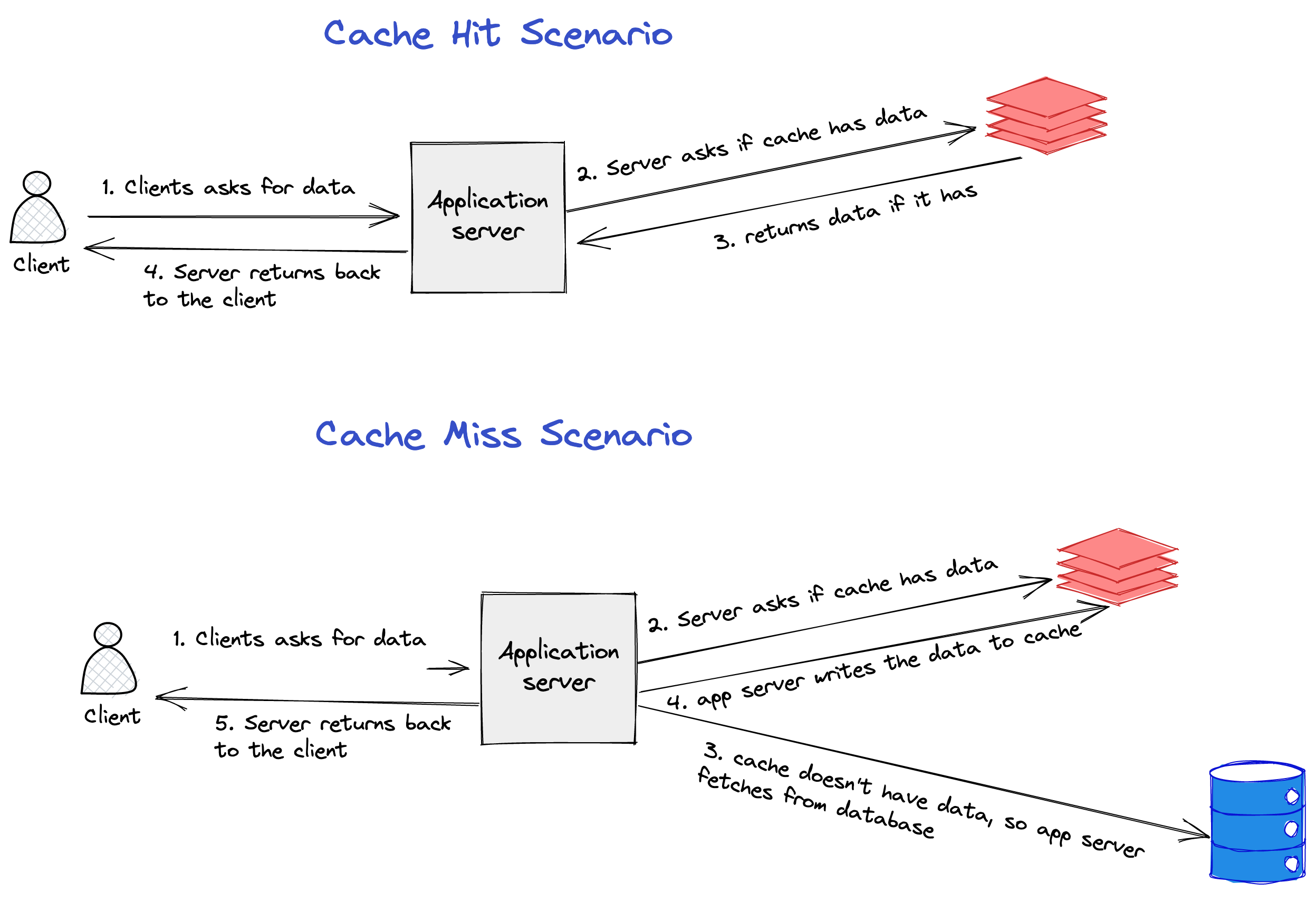
Write Behind
In this pattern, the writes to the cache happen asynchronously through the message queue. The advantage of this pattern is latency is reduced as the writes to the cache are not happening synchronously. But, the downside of this pattern is cache misses increase if there is a lag in writing data to the cache.