HTTP retry and logging using python requests
Introduction
Python’s requests library is a popular library for making HTTP requests. It is a wrapper on python’s built-in urllib module. It gives a clean API with many features. In this post, we will see how to implement retry and logging when using the requests library.
Requests Design
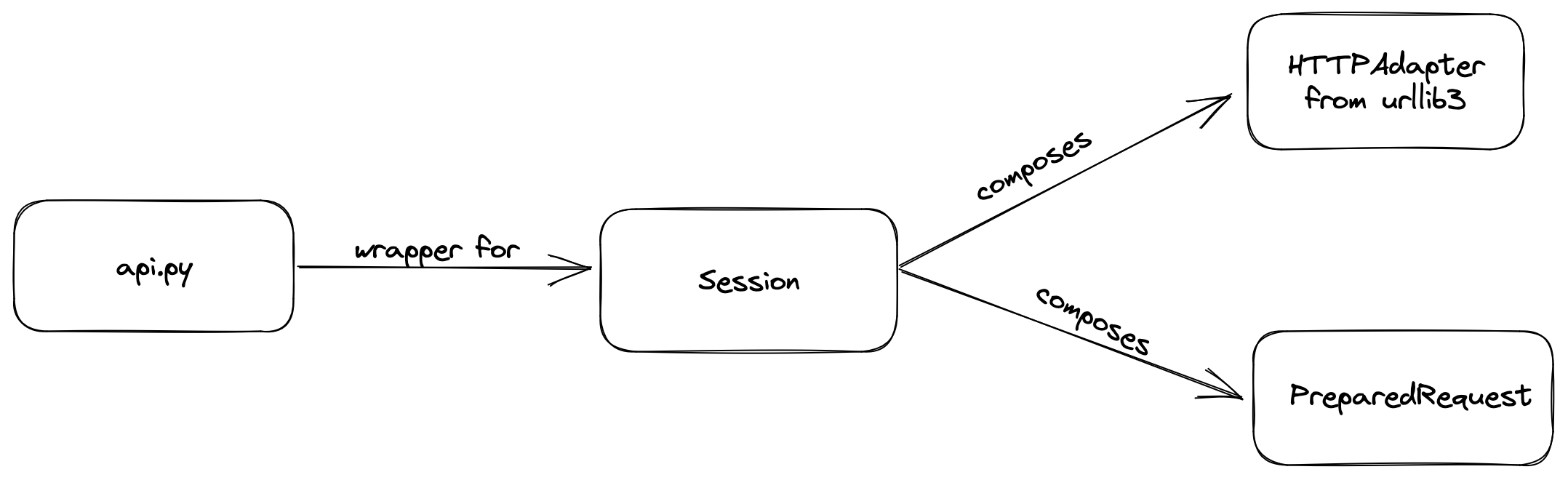
requests is designed modularly using different object oriented patterns. All the methods we use such as requests.get , requests.post etc.. are present api.py which simply creates a session object and sends the request. The Session class present in session.py is the core and heart. It composes HTTPAdapter from urllib3 which is the low-level module in python for sending HTTP requests. It also composes PreparedRequest in models.py which does the preparation of request such as sanitizing input, request body, params etc…
Logging
Why logging is important? it’s a no-brainer! it will be very helpful when troubleshooting issues in a production environment where you can’t debug the program. When building distributed systems, if your application communicates with multiple systems then adding logging to HTTP requests is a must. While logging the request, you can send a unique request id in the headers which helps in tracing the whole lifecycle of the request throughout the system — This is called distributed tracing — I will write a separate blog post on this. Let’s see how can we add logs to python’s requests.
Change the log level of the underlying urllib3 module.
urllib3 provides a handy function called add_stderr_logger which adds a stream handler and sets the level DEBUG by default. We can see the code here for the same.
import requests
import urllib3
urllib3.add_stderr_logger()
resp = requests.get(
"https://jsonplaceholder.typicode.com/posts",
headers={"X-Request-ID": "abcd123"},
params={"foo": "bar"},
timeout=(10, 30),
)The above code prints the following
2023-02-26 23:35:32,110 DEBUG Added a stderr logging handler to logger: urllib3
2023-02-26 23:35:32,166 DEBUG Starting new HTTPS connection (1): jsonplaceholder.typicode.com:443
2023-02-26 23:35:32,352 DEBUG https://jsonplaceholder.typicode.com:443 "GET /posts?foo=bar HTTP/1.1" 200 NoneThis does not log the request headers and body which we may require. So, the only alternative way is to manually log the request and response as we desire. Let’s write a decorator for it.
inherit requests.Session
Just like other HTTP libraries (Axios in javascript), requests do provide hooks or interceptors. A hook is a function that will be called when an event has happened. Unfortunately, requests do not have hooks for the request . It only has for response.
The only way to add logging is to extend requests.Session class and add logging.
class RequestSession(requests.Session):
def request(
self,
method,
url,
params=None,
data=None,
headers=None,
cookies=None,
files=None,
auth=None,
timeout=None,
allow_redirects=True,
proxies=None,
hooks=None,
stream=None,
verify=None,
cert=None,
json=None,
):
logger.debug(f"Before making HTTP request. url={url} method={method}"
f"params={params} data={data}"
f"headers={headers} json={json} timeout={timeout}")
start_time = time.time()
response = super().request(
method,
url,
params=params,
data=data,
headers=headers,
cookies=cookies,
files=files,
auth=auth,
timeout=timeout,
allow_redirects=allow_redirects,
proxies=proxies,
hooks=hooks,
stream=stream,
verify=verify,
cert=cert,
json=json,
)
logger.debug(f"After making HTTP request with params url={url} method={method}"
f"params={params} data={data} headers={headers}"
f"json={json} timeout={timeout} response={response.text}"
f"response_status_code={response.status_code}"
f"response_headers={response.headers} total_time_taken={time.time() - start_time} seconds")
try:
response.raise_for_status()
except requests.HTTPError:
logger.critical(f"HTTP request failed. url={url} method={method}"
f"params={params} data={data} headers={headers}"
f"json={json} response={response.text}"
f"response_status_code={response.status_code}")
return responseIf required, we can always add more details to the logs. Also, make sure to configure the logging level of the module. The below code sets the log levels.
import logging
import requests
import sys
import time
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
handler = logging.StreamHandler(sys.stdout)
handler.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
if __name__ == "__main__":
with RequestSession() as session:
resp = session.get("https://jsonplaceholder.typicode.com/posts", headers={"X-Request-ID": "abcd123"},
params={"foo": "bar"},
data={"a": 1, "b": 2}, timeout=(10, 30)
)Retry
Having retries with exponential backoff is a must in a distributed system to make systems more resilient and fault-tolerant. Let’s see how we can implement retry mechanism with python requests.
The retry mechanism is provided by urllib3 package which is the underlying module of requests.
import requests
from requests.adapters import Retry, HTTPAdapter
retry = Retry(total=10, connect=5, read=5, allowed_methods=['GET', 'POST', 'PUT'], backoff_factor=10, status_forcelist=[500, 502, 503, 504])
session = requests.Session()
session.mount("http://", HTTPAdapter(max_retries=retry))
resp = session.get("https://jsonplaceholder.typicode.com/posts")
print(resp.json())total - the total number of requests to make in total. This argument takes higher precedence which means if you set the total to 10 and other counts higher, the total will be taken.
connect - is the number of retries to make if there is an exception in connecting to the target host.
read - is the number of retries to make if after connecting to the host, if there is any exception in reading data.
allowed_method - Be careful with this. By default, urllib3 includes only idempotent verbs. According to HTTP RFC, GET, PUT, DELETE are the idempotent verbs. When using this, make sure all your verbs are idempotent.
backoff_factor - Number of seconds to wait between two retries. {backoff factor} (2 * ({number of total retries} - 1)) - is the formula to compute backoff time. If backoff_factor is 10, then 5s, 10s, 20s, 40s etc…
status_forcelist - It is the list of status codes on which retries are to be made.
How Retry is Implemented in urllib3
Read this only if you are interested to learn how retry in urllib3 is implemented. In urllib3, connectionpool.py is the core and low-level module for sending HTTP requests. In the function urlopen, if there is any exception then retries.increment is called followed by retries.sleep
retries = retries.increment(method, url, error=new_e, _pool=self, _stacktrace=sys.exc_info()[2])
retries.sleep()The function increment in Retry increments the retry count, checks if the retry limit is exhausted. If yes, then it raises an exception. The code goes on like below.
history = self.history + (
RequestHistory(method, url, error, status, redirect_location),
)
new_retry = self.new(
total=total,
connect=connect,
read=read,
redirect=redirect,
status=status_count,
other=other,
history=history,
)
if new_retry.is_exhausted():
reason = error or ResponseError(cause)
raise MaxRetryError(_pool, url, reason) from reasonNow let’s see what rety.sleep function do. It checks if the response contain the header Retry-After and respects that. If it’s not present, then it gets the backoff time and sleeps.
def sleep_for_retry(self, response=None):
retry_after = self.get_retry_after(response)
if retry_after:
time.sleep(retry_after)
return True
return False
def _sleep_backoff(self):
backoff = self.get_backoff_time()
if backoff <= 0:
return
time.sleep(backoff)
def sleep(self, response=None):
if self.respect_retry_after_header and response:
slept = self.sleep_for_retry(response)
if slept:
return
self._sleep_backoff()